扩展点之SPI
SPI(Service Provider Interface),是JDK内置的一种服务发现机制。思路是:服务调用方制定协议,具体服务提供者实现调用协议。在最终的代码执行上,SPI根据一定的条件查找到合适的服务提供方去执行具体的业务逻辑。
与API的区别:API是服务提供者制定标准,并由服务提供者实现调用协议;SPI是服务调用方制定标准,服务提供方实现的调用协议。
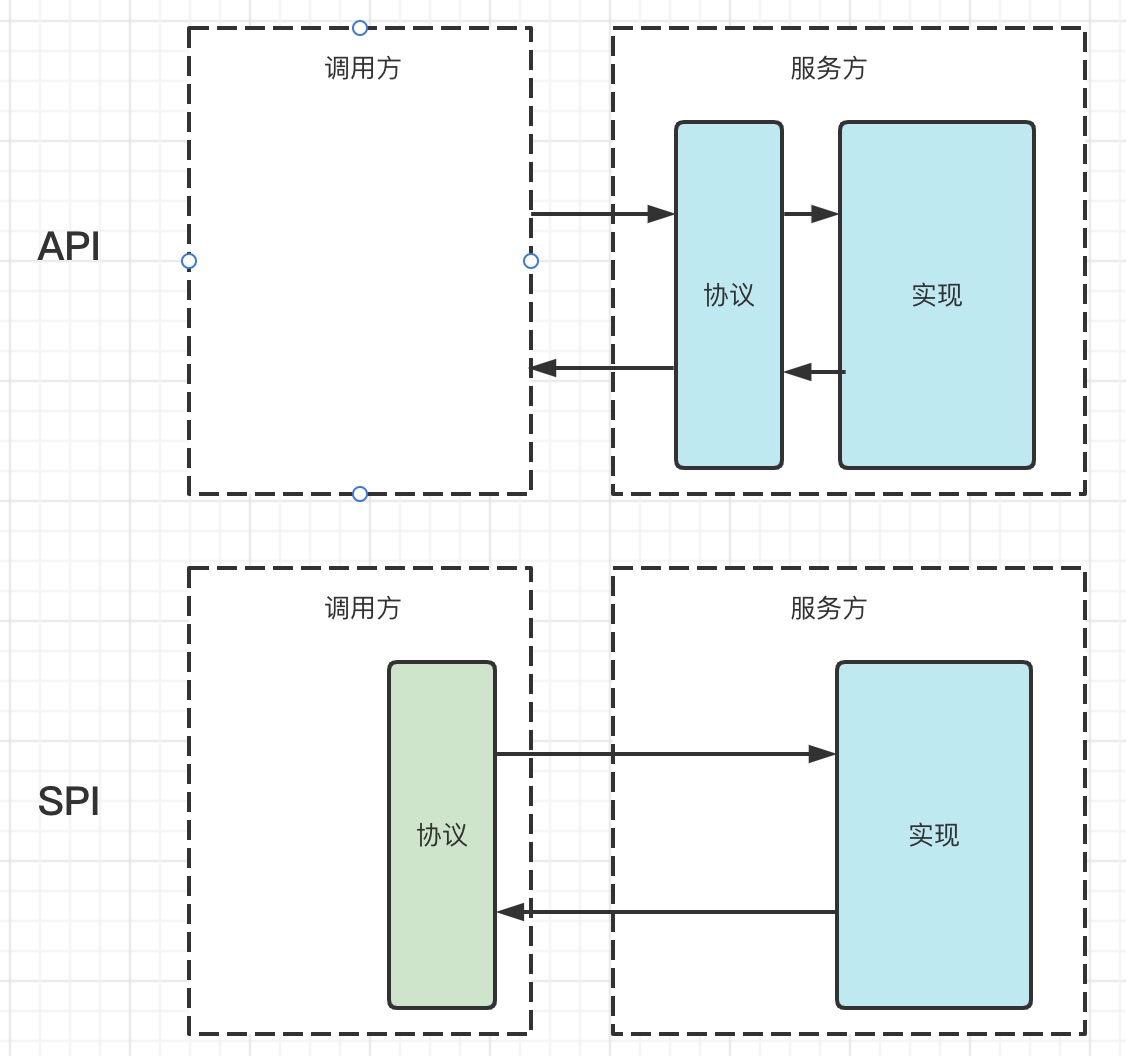
从上图可知,API是服务提供者制定的协议,消费者没办法做选择。在某些场景下,一个服务可能有多个服务提供者,每个服务提供者的实现各不相同。消费者根据实际的业务场景去调用不同的实现。 如果使用API的方案,消费者需要在代码里通过添加分支判断的方式硬编码实现。消费者与服务提供方耦合的比较紧。并且,如果服务提供方比较大的话,消费者的分支代码会越来越大,维护成本越来越高。
如果使用SPI的实现方案,消费者制定统一的协议,由各服务提供者分别实现协议,消费者根据实际情况动态加载服务提供者的实现代码。这样就能更加优雅的实现上述业务场景。
为了实现SPI,JDK约定服务提供方除了要实现服务消费方的接口外,还要在本服务下的resources/MATE-INF/services/下添加一个文件。文件名称必先使接口全路径(包+接口)。在文件中将自己的实现类配置进去,通过换行区分多个不同的实现类。 加载的过程为:
- 初始化ServiceLoader类
- ServiceLoader初始化的过程会遍历所有包下面的resources/MATE-INF/services/目录,查找需要load的服务的实现
- 加载目标类,如果本加载器没找到目标的实现类,需要通过上下文加载器加载对应类
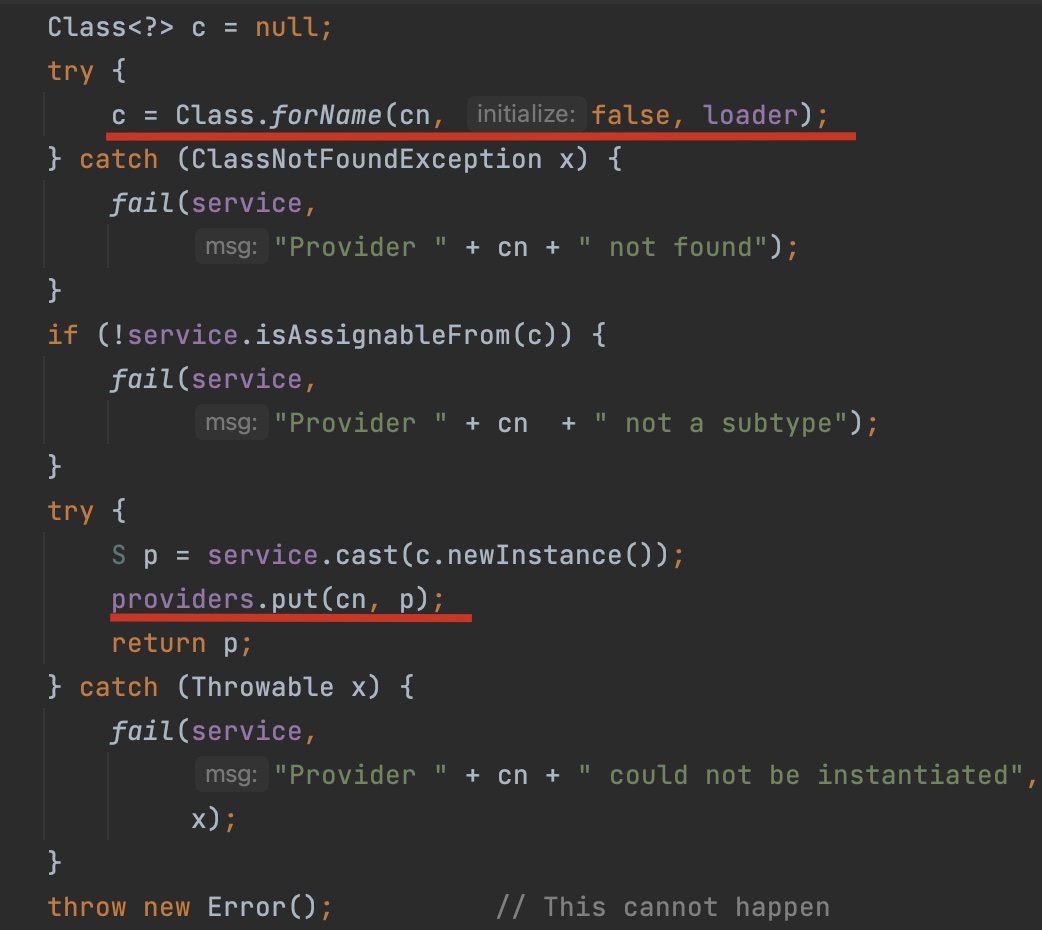
- 实例化目标类,通过Class.forName(cn, false, loader)获取目标类的实例,并将其放入缓存
JDBC(Java DataBase Connectivity),Java规范之一,定义Java操作数据库的一系列操作协议。不同的数据库实现协议定义自己的Connector。业务在操作数据库时,只需要将需要厂商的Connector引入自己的项目中即可。
目前比较流行的数据库驱动包有:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector-version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${pg-connector-version}</version>
</dependency>
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>mssql-jdbc</artifactId>
<version>${ss-connector-version}</version>
</dependency>
以Mysql为例,MYSQL4.0之前的版本都是需要业务手动注册连接器的。4.0之后,MYSQL实现了JDBC的SPI,业务方才无需手动操作注册。 上述Connector中,每个包resources/MATE-INF/services/路径下都有名为com.mysql.jdbc.Driver的文件。 文件中定义了本驱动的Driver实现类全路径。
加载驱动类的核心代码(DriverManager有一个静态代码块):
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// If the driver is packaged as a Service Provider, load it.
// Get all the drivers through the classloader
// exposed as a java.sql.Driver.class service.
// ServiceLoader.load() replaces the sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);【
Iterator<Driver> driversIterator = loadedDrivers.iterator();
/* Load these drivers, so that they can be instantiated.
* It may be the case that the driver class may not be there
* i.e. there may be a packaged driver with the service class
* as implementation of java.sql.Driver but the actual class
* may be missing. In that case a java.util.ServiceConfigurationError
* will be thrown at runtime by the VM trying to locate
* and load the service.
*
* Adding a try catch block to catch those runtime errors
* if driver not available in classpath but it's
* packaged as service and that service is there in classpath.
*/
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
println("DriverManager.initialize: jdbc.drivers = " + drivers);
可以看到,驱动加载使用了ServiceLoader类。具体的加载过程与SPI加载流程一致。
- 定义SPI
/**
* @describe:
* @author: melonkid
* @date: 2022/12/6 11:30
*/
public interface TestSPIServer {
void sayHello();
}
- 定义不同的SPI实现 Impl1、Impl2
/**
* @describe:
* @author: melonkid
* @date: 2022/12/6 11:30
*/
public class TestSPIServerImpl1 implements TestSPIServer {
@Override
public void sayHello() {
System.out.println("hello TestSPIServerImpl1");
}
}
/**
* @describe:
* @author: melonkid
* @date: 2022/12/6 11:30
*/
public class TestSPIServerImpl2 implements TestSPIServer {
@Override
public void sayHello() {
System.out.println("hello TestSPIServerImpl2");
}
}
- 配置SPI实现,在实现类所在的包resources/MATE-INF/services/路径下添加cn.melonkid.study.TestSPIServer文件 文件内容如下:
cn.melonkid.study.TestSPIServerImpl1
cn.melonkid.study.TestSPIServerImpl2
注意:上面的接口和实现可以在不同的jar包中。这里为了简单就放到一个jar内了。
- 加载并执行SPI
/**
* @describe:
* @author: melonkid
* @date: 2022/12/6 11:30
*/
public class TestSPIServerTester {
public static void main(String[] args){
ServiceLoader<TestSPIServer> loader = ServiceLoader.load(TestSPIServer.class);
for(TestSPIServer l : loader) {
l.sayHello();
}
}
}
输出日志
Connected to the target VM, address: '127.0.0.1:50691', transport: 'socket'
hello TestSPIServerImpl1
hello TestSPIServerImpl2
Disconnected from the target VM, address: '127.0.0.1:50691', transport: 'socket'
看到这里,相信大家可以知道,SPI其实可以作为扩展点的一种实现方案。所谓扩展点,就是在业务流程或则代码流程中预留的能力。这部分预留的能力需要不同的使用方根据实际情况去加载具体的实现服务。 举个场景:APP个性化广告场景,一个C端APP可能包含很多子业务。APP可能需要根据运营需求、节日、业务推广活动等进行动态的个性化广告推荐。 加入APP广告推荐是一个业务平台服务,那他就需要对接各种业务的广告推荐需求。如果要保持平台代码的简洁和可维护性,就必先抽象出业务流程和扩展点。 针对上面场景,我们定义一个简单的业务流程。
获取用户信息 -> 校验推送 -> 加载推送规则 -> 获取推送模板 -> 获取广告内容 -> 组装广告
| 业务用例 | 描述 | 是否可做扩展点 |
|---|---|---|
| 获取用户信息 | 加载用户信息,用来为后续推送决策提供基础数据 | 否 |
| 推送校验 | 判断推送功能是否降级,当前用户是否可以推送;如果可以推送,获取用户的个性化推送策略 | 否 |
| 加载推送规则 | 根据用户信息和推送策略加载推送规则,规则一般维护在平台侧,由平台运营同学根据情况进行配置 | 否 |
| 获取推送模版 | 根据规则加载广告模板,模板可能维护在平台侧或则也可以维护在业务侧;维护在业务侧的好处是业务可以灵活的调整模板 | 是 |
| 获取广告内容 | 根据模板,获取广告内容;内容最好也维护在业务侧。因为广告内容业务个性化比较重。平台不应该感知业务细节 | 是 |
| 组装广告 | 模板引擎对广告进行解析和组装,最终生产广告数据 | 否 |